
Deploying a new version of a product to production is one of the most critical moments in the Software Development Lifecycle. It can go from sheer excitement to release the latest features, to a nightmare of cascading failures and outages. In this series of posts, we will explore deployment techniques that can be used to deploy a new version of an application without causing disruption to end users.
Introduction
It is time to deploy a new version of the product. All the development work is done, the tests have passed, and the stakeholders approved it. Now we need to schedule a maintenance window in the middle of the night on a weekend, stop traffic to all servers, update the software following a lengthy procedure with lots of manual steps, restore traffic to the servers and hope everything works.Sounds risky, right? This has been the standard way of doing deployments for a long time. Fortunately, there are better ways. On this Zero Downtime Deployment Techniques series of posts, we will highlight three of the most common ways of deploying software without downtime. The first technique we will look at is Rolling Updates, followed by Blue-Green deployments and Canary deployments.
Rolling Updates
Given an application deployed to production with multiple instances receiving traffic, a rolling update will incrementally update or replace the instances until all of them are running the desired version. The number of instances updated at each stage follows a predetermined rate, and eventually reaches 100%.
In order to apply this technique, your application needs to be able to run multiple instances at the same time, potentially with different versions. There must be a load balancer or reverse proxy to distribute traffic among all of them. Finally, it is necessary to have a method to determine if an instance is healthy and ready to serve traffic.
How it Works
Let’s say you have 3 instances of the application running and serving traffic. The first step is to stop serving traffic to one of the instances and either update the software or replace it with another instance running the desired version. Once the instance with the new version is created or updated, a simple test is run to verify that the instance is healthy and can start receiving traffic. When the test passes, the instance is added to the pool of instances serving traffic.
When the process for one instance is complete, the same procedure is executed for the next instance, until all of them are running the desired version. Since there are always a few instances running at any given time, current or new, the application is operational all the time and no downtime is experienced.
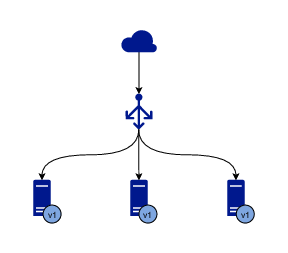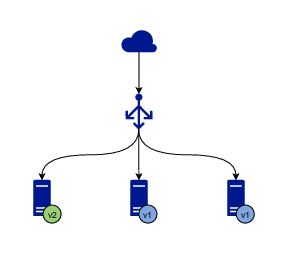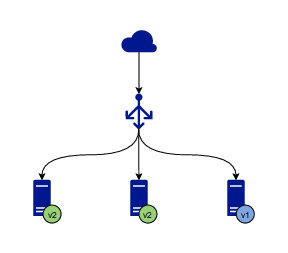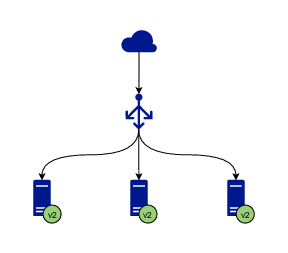
A rolling update of 3 instances
Parameters
The procedure does not need to happen one instance at a time, and it is usually possible to tune it based on the number of instances currently running and the number of instances that must be up at any given time. Which parameters are available and the semantic of them will depend on the infrastructure platform you are using.Let’s take a look at the parameters provided by the Kubernetes platform when performing rolling updates of deployments.
Max Unavailable
This parameter controls how many instances can be unavailable at any given time during the deployment. The value can be an absolute number or a percentage of the total number of instances.Let’s say we have a deployment with 10 instances and we have set Max Unavailable to 30%. This means that the deployment procedure can stop 3 instances immediately and start replacing them with new ones. When an instance is done, new ones can be stopped and replaced, until all of them are updated. This ensures that at least 70% of the instances will be up at any given time.
Max Surge
This parameter controls the maximum number of instances that can be created in addition to the desired target. The value can be an absolute number or a percentage of the total number of instances.Using the same example as above, if we have a deployment with 10 instances and we have set Max Surge to 30%, it means that the deployment procedure can start 3 instances immediately and start configuring them. When old instances are terminated, new ones can be created and configured, until all of them are updated. This ensures that the number of instances does not exceed 130% of the desired capacity.
Possible Challenges
When implementing this technique, there can be some challenging situations depending on the nature of your workload. In this section, we will list common problems and possible solutions.Stateful applications
If used to deploy stateful applications, transient information that is stored in the instance (like user sessions, cached files, etc.) might be lost when an instance is updated or replaced.If it is not feasible to store this information outside of the instance, a possible solution is to stop new traffic to old instances, but let them finish the processing of ongoing requests or sessions. New requests and sessions will be routed to new instances and old instances must be cleaned up after they become idle.
Concurrent versions
One of the most common challenges in rolling updates is supporting two versions of the application running at the same time. The new version must be implemented with the old version in mind, parts of the architecture or data schema cannot be just removed from one version to the next, intermediary versions may be necessary in order to deprecate such components and only after 2 or 3 versions, they can be deleted. It is important to consider both backward and forward compatibility.Backward compatibility
The new version of the application should be able to process data created by the old version. One-time migration scripts usually do not work in this scenario since the versions will be running concurrently and the old version will still be creating new data that can potentially be processed by the new version.
Forward compatibility
The old version of the application must be able to work with data created by the new version. This usually means that the old version must be able to handle extra fields in a database table or event schema without crashing. For instance, if the database schema is modified during the update to add an additional column, it is important to ensure that the previous version will still be compatible with the new schema.
When to Use
This technique can be used whenever your application supports running multiple instances with different versions at the same time. This is the simplest technique to implement among the three that we will cover (the other two are Blue-Green and Canary deployments) and should be a good first step towards Zero Downtime Deployments.Key Takeaways
If you are planning on using this technique on a brand-new project, keep in mind the challenges listed above and design your application and data schemas to be forward and backward compatible.If your plan is to introduce this technique on a running project, you may need to first make architectural changes to your system. These changes may include:
- Make the application stateless by storing state in an external service like a database or a key-value store.
- Support more than one instance of the application running at the same time. You may need to introduce a load balancer and check for potential concurrency issues.
- Introduce tests to ensure the application is backward and forward compatible. It may be necessary to change code to support extra parameters on database tables and event schemas.
Acknowledgment
This is the first of an article series being written by Isac Sacchi Souza, Principal DevOps Specialist, Systems Architect & member of the DevOps Technology Practice. Thanks to João Augusto Caleffi and the DevOps Technology Practice for reviews and insights.About Encora
Fast-growing tech companies partner with Encora to outsource product development and drive growth. Contact us to learn more about our software engineering capabilities.References
- Schenker, Gabriel N et al. Getting Started with Containerization. Packt Publishing, 2019.
- Yilmaz, Onur. Kubernetes Design Patterns and Extensions. Packt Publishing, 2018.
- Kubernetes Rolling Updates Deployments. Accessed on Nov, 2021. https://kubernetes.io/docs/concepts/workloads/controllers/deployment/#rolling-update-deployment
